
히히 벌써 팀 프로젝트 두 번째 편입니다.
첫 번째 편에는 프로젝트 기획 방향에 관해
소개해 드렸었는데요!
오늘은 분석 프로젝트의 대주제인
우주선 타이타닉호 승객 예측을 위해
데이터 전처리 및 EDA를 해볼 예정입니다.
본격적인 전처리를 시작하기 전에,
데이터에 관해 자세히 소개해 드릴게요!
[데이터셋 확인]
데이터는 아래 주소에!
https://www.kaggle.com/competitions/spaceship-titanic/data
데이터는 총 3개로 구성되어 있어요.
|
train
|
학습 데이터
|
|
test
|
평가 데이터
|
|
sample_submission
|
kaggle 제출 파일
|
다음은 변수를 확인해 볼게요.
이번 데이터는 지금까지 진행했던 분석 중
변수가 가장 많았어요. 총 14개!
|
PassengerId
|
탑승객에 대한 고유 ID
|
|
HomePlanet
|
탑승객이 출발한 행성
|
|
CryoSleep
|
일시 중단 옵션 여부
|
|
Cabin
|
객실 번호
|
|
Destination
|
목적지
|
|
Age
|
나이
|
|
VIP
|
VIP 서비스 비용 지불 여부
|
|
RoomService
|
룸서비스 지불 금액
|
|
ShoppingMall
|
푸드코트 지불 금액
|
|
Spa
|
스파 지불 금액
|
|
VRDeck
|
VR 데크 청구 금액
|
|
Name
|
이름
|
|
Transported
|
다른 차원이동 여부
|
범주형 변수
PassengerId, HomePlanet, CryoSleep(T/F), Cabin
Destination, VIP(T/F), Name, Transported(Target T/F)
(cabin, name은 텍스트 데이터)
연속형 변수
Age, RoomService, FoodCourt,
ShoppingMall, Spa, VRDeck
[EDA 및 결측치 처리]
데이터셋을 확인한 후 팀원분들과
변수를 나누어 데이터를 더 자세히
살펴보는 시간을 가졌어요.
각자 맡은 변수에서 결측치, 이상치,
분포 편중, 중복 컬럼 등이 있는지
조사해서 공유하였답니다.
제가 맡은 변수는 age, destination, cabin
변수였는데요. 변수의 기본적인 특징을
확인하기 위해서 아래와 같은 함수들을
이용해 간단하게 분석하였습니다.
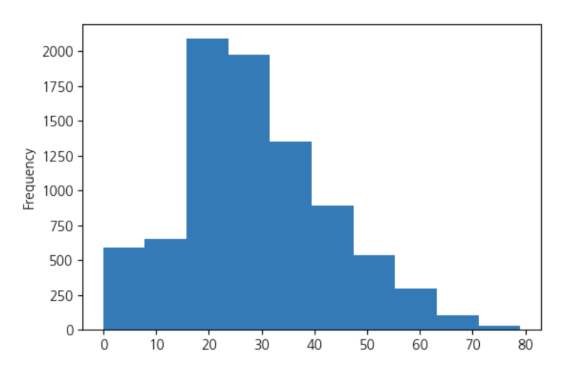
히스토그램을 그려보고, min, max, agv, 0값, 그리고
결측치 여부 등 기본적인 특징을 알아보았어요.


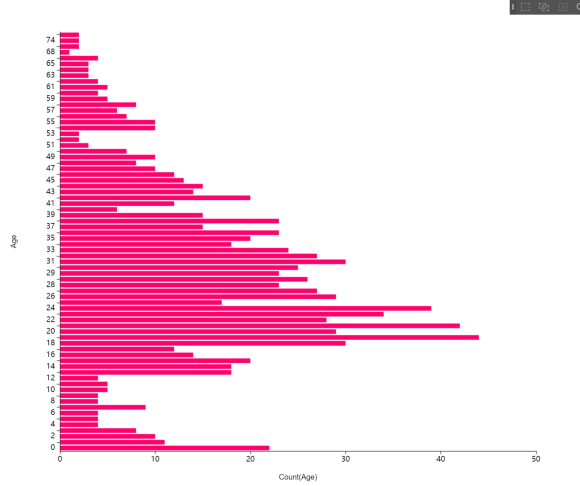
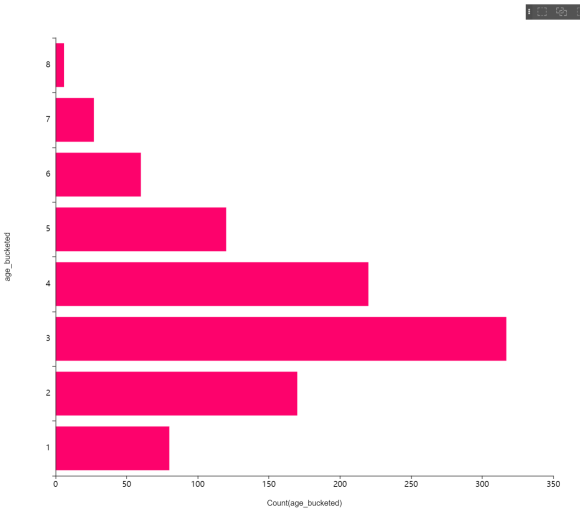
또 브라이틱스내의 차트 기능을 이용해
EDA도 함께 진행해 보았답니다.
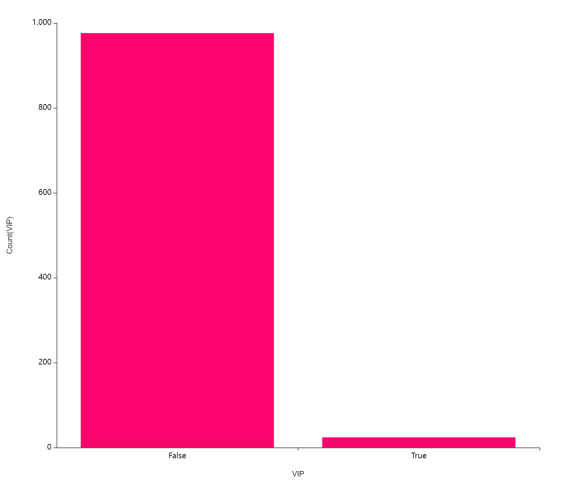
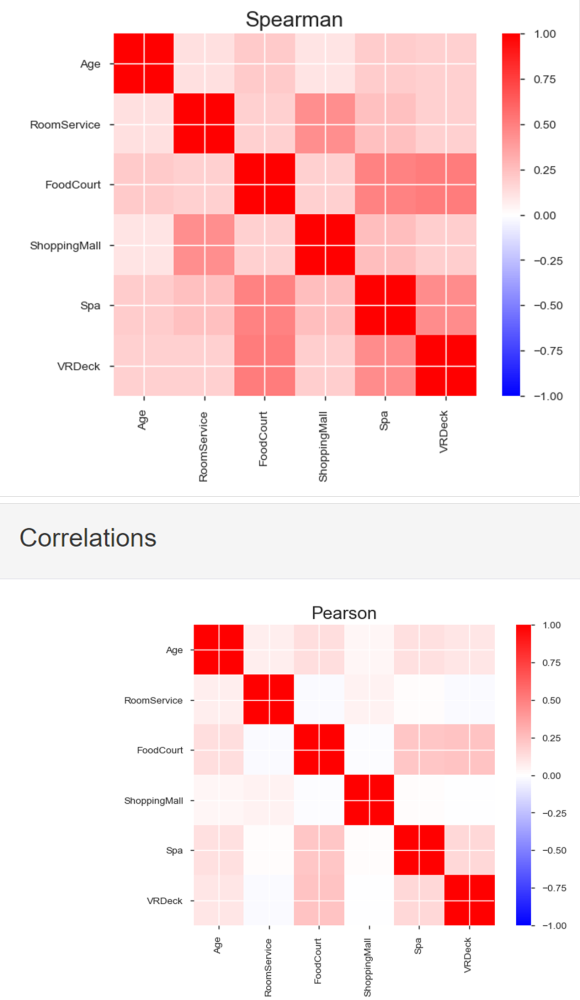
상관계수 분석도 진행하였어요.
이렇게 각자 변수들을 파악한 후
회의를 통해 특징들을 공유했어요.
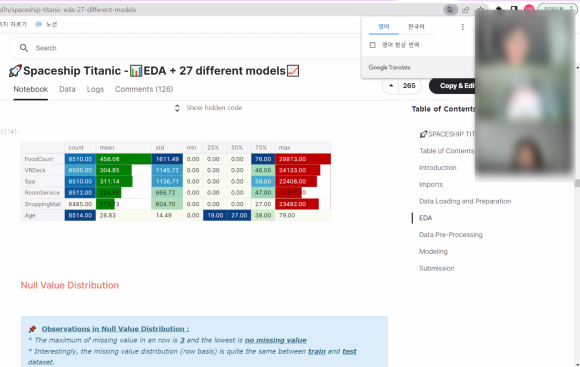
회의를 진행하며 결측치를 어떻게 처리할
것인지에 관한 아이디어를 나누었습니다.
여기서 한 가지 알게 된 팁은 바로
캐글 내의 코드 카테고리입니다.
빨간 박스로 체크된 부분을 클릭하면
다른 사람들의 분석 과정을 볼 수 있답니다.
이 기능을 활용해 더 나은 모델을 구상하기 위한
아이디어를 참고할 수 있었어요!
여러 의견을 종합해 최종적으로
1. 나이 변수를 범주화하고,
2. 결측치 최빈값 혹은 평균값 대치,
3. 범주형 변수 불균형 데이터
로그 변환 과정을 진행하기로 했어요.
현재 범주형 변수 불균형 데이터까지
진행된 상황이고, 다음 회의 시간까지
데이터를 조금 더 살펴보며 특정한 패턴을
찾아 결측치를 처리하는 2차 전처리 과정을
진행하기로 했답니다!
그러니 다음 주에는 2차 전처리 과정과
모델링이 진행되겠죠?
그럼 다음 주에 만나요 ♡
*본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
'삼성 SDS Brightics 서포터즈 3기' 카테고리의 다른 글
| [Brightics 서포터즈] 팀 분석 프로젝트 (마지막 편) (0) | 2022.09.06 |
|---|---|
| [Brightics 서포터즈] 팀 분석 프로젝트 (3편) (0) | 2022.08.31 |
| [Brightics 서포터즈] 팀 분석 프로젝트 (1편) (0) | 2022.08.16 |
| [Brightics Studio] 영화 데이터로 군집 분석 진행하기(K-means_개인미션③) (0) | 2022.07.12 |
| [Brightics studio] 발 사이즈로 키 예측하기 _ 개인분석(2) (0) | 2022.07.05 |



