
안녕하세요! 오늘은 우주선 타이타닉호 승객
예측 프로젝트 마지막 편으로 찾아왔어요.
잠시 지금까지 했던 팀 프로젝트
포스팅 글을 요약해 보도록 할게요!
1편 - 프로젝트 소개
2편 - 데이터셋 탐색, EDA, 1차 전처리
3편 - 2차 전처리, 모델링
이렇게 3주 동안 팀 프로젝트가 진행됐는데요.
지난 시간에 모델링까지 끝났기 때문에
오늘은 모델링 그 후!를 살펴보는
시간을 가져보도록 하겠습니다.
<변수별 중요도>
먼저 사용했던 모델의 (랜덤 포레스트, XGB)
영향인자를 확인해 보겠습니다.
영향인자는 이번 프로젝트의 타겟 변수인
Transported 예측에 가장 기여를 많이 한
변수를 의미합니다.
영향인자는 브라이틱스 스튜디오에서
쉽게 확인이 가능한데요.
Random Forest Classification Train
함수를 적용한 뒤 Run을 눌러주시면
결과 칸에 아래와 같은 이미지가 뜹니다,
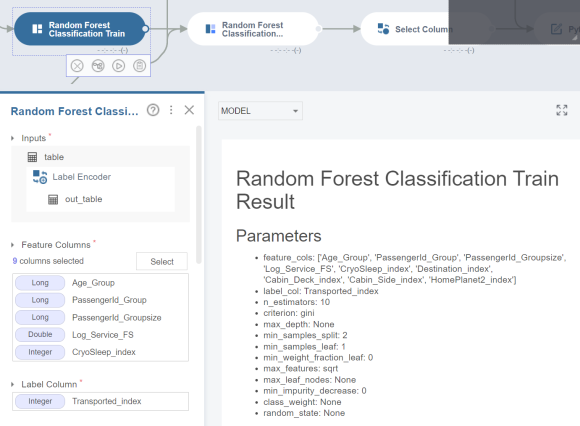
Random Forest Classification Train Result
부분을 확인하면 파라미터와 영향인자를
확인할 수 있답니다!
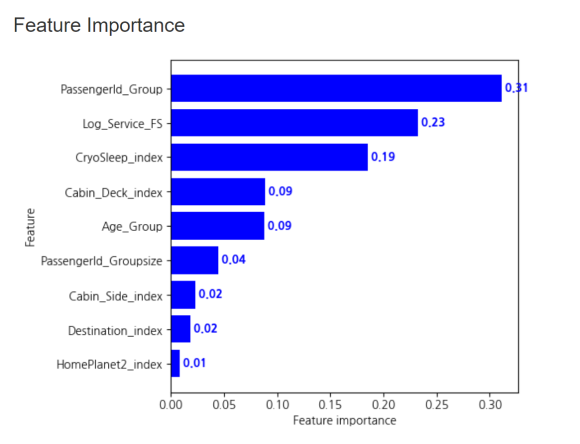
랜덤 포레스트 모델에서 Transported 예측에
가장 기여를 많이 한 변수는 Passengerld Group입니다.
그다음으로는 servie 중 foodcourt와 shoppingmall
변수를 합한 service_FS가 높게 나왔네요!
다음으로는 XGB Classification Train 모델은
어떤 또 다른 결과를 보여주고 있을지
확인해 보겠습니다.
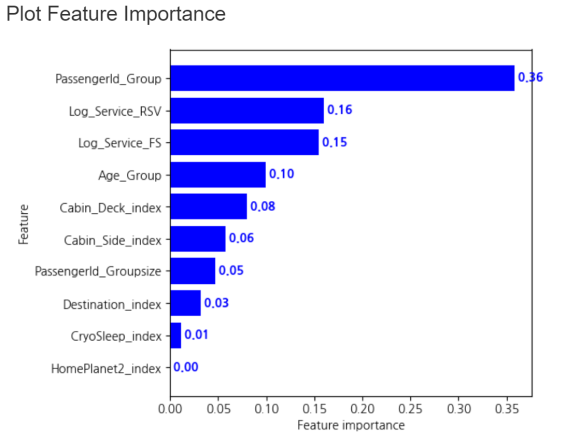
XGB 모델에서는 랜덤 포레스트와
조금 다른 결과가 나왔는데요!
1위는 동일하게 Passengerld Group이지만
2위는 Service_RSV이네요.
이번 분석을 진행하며 처음으로 변수별 중요도를
파악해 보았는데요. 모델마다 변수별 중요도가
다르게 적용되는 게 흥미로운 지점인 것 같아요.
<모델 성능 확인>
다음은 4팀에서 만든 모델 성능을
확인해 보도록 하겠습니다.
이번 프로젝트에서 모델 성능을 확인하기
위해서는 캐글에 직접 제출해야 했는데요.
이를 위해 0과 1으로 나온 예측 값을
T/F 형식으로 바꾸어 주었어요.
이 부분은 파이썬 스크립트를 활용하였습니다.
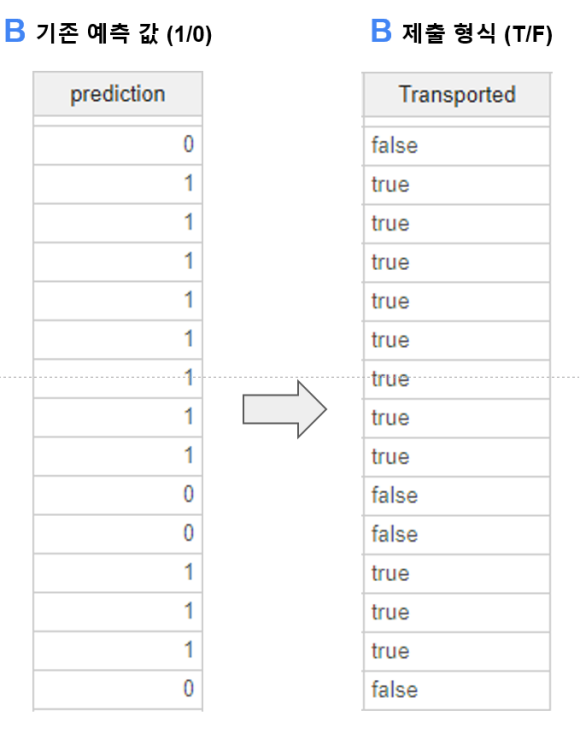

이렇게 변환한 파일을 캐글에 제출해 주었는데요!
결과는 아래와 같았습니다.
랜덤 포레스트 ⭢ 0.49286
XGBBOOST ⭢ 0.49427
이번 분석에는 XGB 모델이 더 높은 예측
정확성을 보여주었네요! 위와 같은 결괏값은
전체 탑승 객 중 약 절반에 가까운 탑승객의
수송 여부를 맞췄다는 걸 나타냅니다.
코드 공유를 해주셨던 다른 분들의
점수를 슬쩍 살펴보니 상당히 높은 정도의
예측을 성공하신 분들이 많더라고요!
팀원 분들과 이야기를 나눠 본 결과,
지금보다 성능을 더 올리기 위해서는
추가적인 파생 변수 생성, 스케일링,
모델 앙상블 등 다양한 시도가
필요할 것 같다는 이야기가 나왔었어요.
만일 다음 분석을 진행하게 된다면
팀 프로젝트를 진행하면서 보완해야 겠다고
생각한 것들을 진행해보면 좋을 것 같다는
생각이 마구마구 들었답니다.
타이타닉 호 탑승객 예측 프로젝트는
이렇게 마무리 되었습니다!
처음으로 캐글에 점수도 올려보고,
나온 점수로 더 발전 가능성까지 검토를 해보니
정말이지 얻어 간 게 많은 프로젝트라는
생각이 들었답니다 ㅎ.ㅎ
참고로 이번 포스팅은 멘토님이 보내주신
피드백을 바탕으로 작성되었답니다.
감사합니다 ♡
벌써 마지막 팀 분석 프로젝트 포스팅이라니
아쉬운 기분이 들기도 하지만! 다음 주부터는
또다시 재밌는 주제로 돌아올 것이니 너무
아쉬워하지 않겠어요. 그럼 모두 빠잉
*본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.
'삼성 SDS Brightics 서포터즈 3기' 카테고리의 다른 글
| [Brightics 서포터즈] 와 소리 나는 4조 영상 제작기!!! (촬영 2편) (0) | 2022.09.21 |
|---|---|
| [Brightics 서포터즈] 똑 소리 나는 4조 영상 제작기!!! (기획 1편) (0) | 2022.09.16 |
| [Brightics 서포터즈] 팀 분석 프로젝트 (3편) (0) | 2022.08.31 |
| [Brightics 서포터즈] 팀 분석 프로젝트 (2편) (1) | 2022.08.23 |
| [Brightics 서포터즈] 팀 분석 프로젝트 (1편) (0) | 2022.08.16 |



