[Brightics studio] 노코드 AI 오픈소스 브라이틱스로, 광고 클릭 여부 예측하기 (모델링 2&평가 ⑤)

하이
지난번에 이어 두 번째 모델링을
진행한 후 평가까지 진행하도록 할게요.
문제 해결

지난 시간 XGB regression 모델을 이용해
광고 여부 클릭 예측을 해보았는데요.
제 생각과는 다르게 결괏값이 나와서
(클릭 여부이니까 0혹은 1로 결괏값 예상)
이리저리 찾아보다 멘토님께 도움을
요청했습니다.
메일을 보내고 얼마 지나지 않아 답변을 주셨는데요.

이렇게 XGB Regression 모델이 아닌
XGB Classification 모델을 활용하는 방식이
가장 간단할 것 같다는 해결책을 주셨어요.
요런 방법이
멘토님의 조언을 받아 모델을 교체해 보았습니다.
train 함수와 predict 함수를 순차적으로
연결해 준 뒤 결괏값을 확인해 보았습니다.

0과 1의 예측 값을 얻을 수 있었습니다.
추가로, 생각했던 문제를 해결했지만 멘토님께서
하지만 xgb regression이 틀린 방법은 아니라고
알려주셨는데요,
Regression 예측값을 a(0~1 사이의 값)
이상 값 1, a 미만 값 0으로 변환해서
사용할 수 있다고 합니다 ㅎㅎ
모델 학습 & 정확도 (1)
그렇다면, Classification 종류의 함수들을
사용해 좀 더 다양한 모델을 학습시켜볼게요.
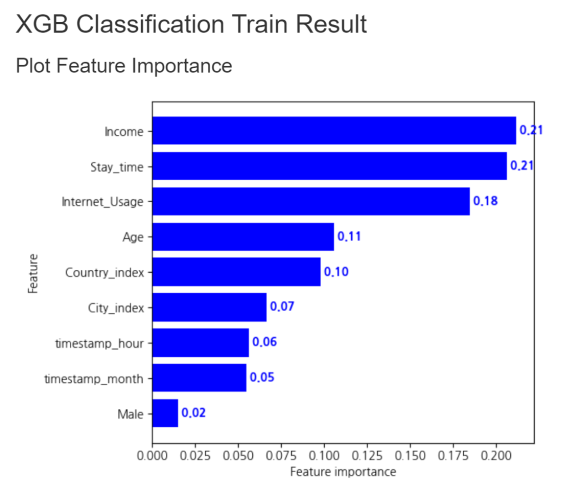
우선 가장 먼저 학습한 xgb classification의
plot feature importance입니다.
income 변수가 0.21으로 가장 중요하고
그다음으로는 stay_time, internet_usage, age
등의 변수가 뒤를 잇고 있습니다.
추가로 xgb classification 모델은
앙상블 부스팅 모델입니다.

학습을 시켜준 뒤, 학습 데이터를 바탕으로
predict 값을 생성해 주었어요.
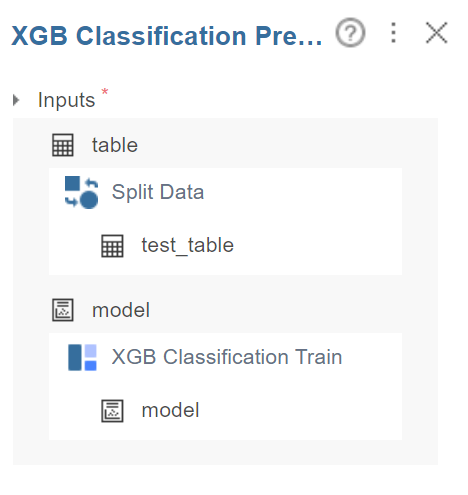
predict 함수에서 inputs 부분에서
train 데이터와 test 데이터가 섞이지
않았는지 검토한 뒤,
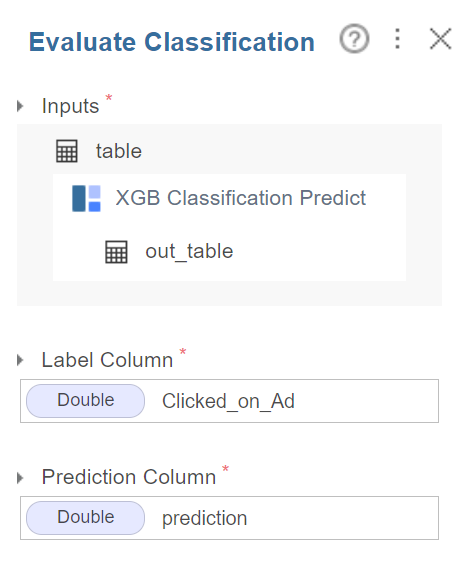
evaluate Classification 함수를 사용하여
모델을 평가하였습니다.
label column은 clicked_on_ad
그리고 prediction column은 새로
생성된 prediction을 넣어주었어요.


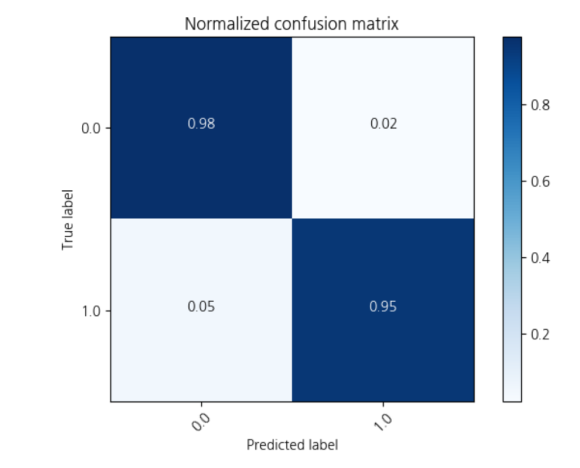
모델의 정확도가 약 96%가 나왔는데요.
정확도가 너무 높게 나와 생각을 해보니,
매우 인위적으로 만들어진 데이터셋이
원인이지 않을까 생각해 봅니다.
다른 분들의 결과를 봐도 정확도가
90-6을 웃도는 경우가 많더라고요.
처음 데이터셋 선정부터 평가까지
분석 과정 중 중요하지 않은 부분이
없다는 걸 다시 한번 알게 되는 것 같아요.
모델 학습 & 정확도 (2)
다음으로는 adaboost classification
모델을 사용하였습니다.
adaboost classification 모델은
오류 데이터에 가중치 부여를 통해
오류를 개선해나가며 학습하는 방식입니다.

이번에도 마찬가지로 동일한 방식을 사용해
모델을 생성해 주었습니다.
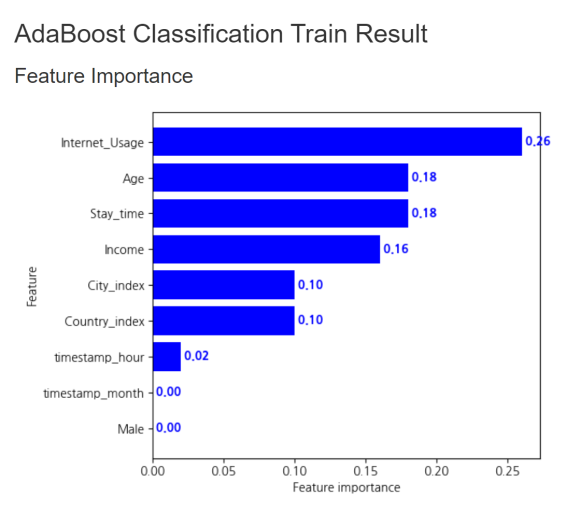
plot feature importance를 살펴볼게요.
지난번 xgb 모델과 다르게 internet_usage
변수가 0.26으로 가장 높게 나왔습니다.
그 뒤로는 age, stay_time, income
순서대로 중요도가 높습니다.
month와 male 변수는 0.00이 나왔네요.



ada 모델의 경우 정확도가 0.9563758... 정도로
xgb 모델과 비슷한 정확도를 보여줍니다.
모델 학습 & 정확도 (3)
다음은 knn classification 모델입니다.
knn classification 모델은 각 데이터들 간의
거리를 측정하여 가까운 k 개의 다른 데이터의
레이블을 참조해 분류/예측을 하는 방법입니다.

이렇게 두 단계를 거쳐줄게요.
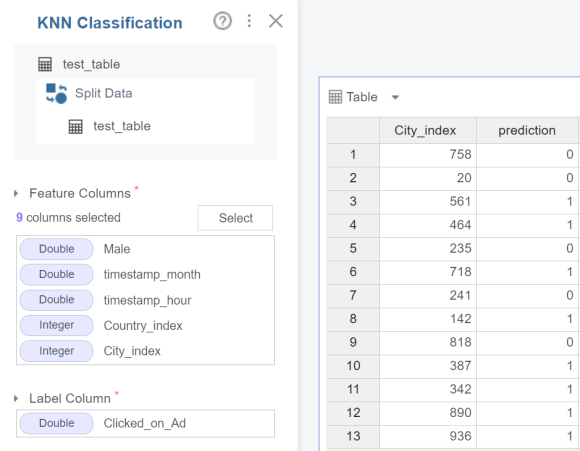
변수들을 선택해 주고, label column에
clicked_on_ad을 넣어줍니다.
run을 누르면 다음과 같이 예측값이
생성되게 됩니다.

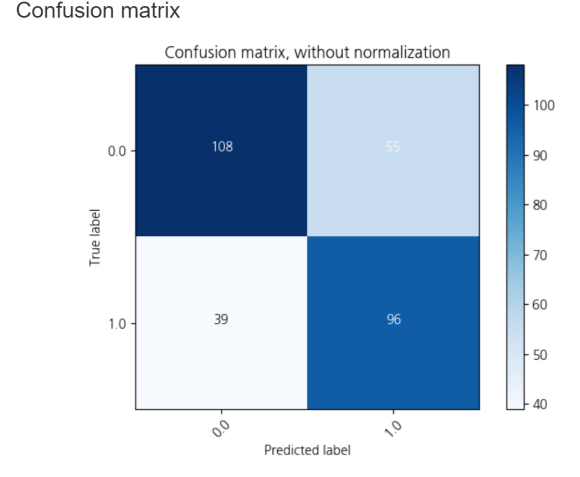
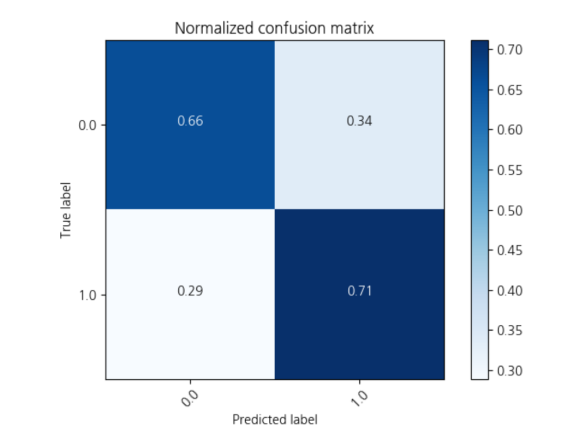
knn classification 모델의 정확도는
0.68456378389... 정도로 약 0.69이네요!
오늘은 이렇게 총 세 가지의 모델을 살펴보았습니다.
다음 주에는 프로젝트의 부족했던 부분들을 살짝
채워보고, 전체적으로 리뷰해 보는
시간을 갖도록 할게요!
+
그리고 반가운 소식 한 가지를 들고 왔습니다.
Brightics Studio와 Education의 통합 버전이
새로 출시되었다는 소식입니다!
브라이틱스는 원래 ai, studio, education 버전으로
나누어져 출시되었는데요. 이 중 studio와 education이
통합되었다고 해요.
새로 출시된 버전은 데이터 분석을 위한 함수를
200개 이상 제공하고, 함수 즐겨찾기,
국/영문 설정을 지원하여 보다 편리하게
데이터 분석을 할 수 있어요.
아직 데이터 분석에 거리감이 있으신
분들이라면 쉽게 접근할 수 있는 통합 버전을
추천드릴게요!

새로운 통합 버전을 설치하기 전에
주의사항이 두 가지가 있는데요.
※ 통합 버전 설치 시, 기존 Studio는 삭제 후 설치하기
※ 삭제 전 작업한 JSON 파일은 꼭 별도 저장 및 보관하기
이 두 가지를 꼭 기억해 주세요!
삭제 전 작업물들이 모두 날아가 버리는
불상사를 막기 위해 보관은 필수!
그럼 다음주에 만나요
*본 포스팅은 삼성SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다.